- Cloud Security Lab a Week (S.L.A.W)
- Posts
- Serverless Security 101
Serverless Security 101
In part 5 of our Epic Automation series we'll learn the basics of Lambda functions and how to use them securely, even for security, because we like security.
Rich Mogull
March 06, 2025 • Estimated Reading Time: 11 minutes
CloudSLAW is, and always will be, free. But to help cover costs and keep the content up to date we have an optional Patreon. For $10 per month you get access to our support Discord, office hours, exclusive subscriber content (not labs — those are free — just extras) and more. Check it out!
Prerequisites
This is part 5 of the Advanced Cloud Security Problem Solving series, which I’ve been abbreviating to Epic Automation. If you haven’t done parts 1-4 yet, jump back to the first post in the series and complete all prior posts before trying this one.
The Lesson
Over the past four labs we’ve built out the foundation of our automation platform by wiring together our centralized event bus, using a simple EventBridge rule and SNS to validate that the pipeline works. This week we’ll set up our first Lambda function, which is where all application logic will live.
Oh, never heard of Lambda functions? Or never worked with them before? Yeah, this is where things get pretty awesome.
Serverless 101
Let’s clean up some terminology to start. Everything I’m about to cover is more on the development and operations side, but you can’t secure things you don’t understand.
Serverless is the term we use for cloud services you use where you don’t manage the underlying servers. Huh? Think of it this way: with EC2 we ran an instance and we handled all the configuration of the software and the operating system. We are responsible for scaling, sizing, and overall management. S3? It’s just a… thing… where we put files, and we can configure it to serve those files like a web server, without installing or managing any web server software. We have no idea what’s under the hood and we never touch an operating system. EC2 isn’t serverless, but by my definition (which not everyone agrees with), S3 is. Especially if you configure it for use as a web server.
It’s a little confusing because some people (okay, a lot) tend to only use the term serverless when referring to Function as a Service (FaaS). What’s FaaS? It’s a kind of workload, which is a term we use to describe where code runs. It’s easier to understand what FaaS is if we list the major workload types:
Physical server: If I need to explain what this is you probably skipped ahead a few posts, and should come back after learning the alphabet.
Virtual Machine (VM): We run our code/application in a full operating system on a hypervisor. An EC2 instance is a virtual machine.
Container: Containers encapsulate an application and its dependencies. They usually run on a VM or physical host, on top of an operating system in a little isolated bubble. Some containers are heavy, very like a full virtual machine, while others are very lightweight (which is how they should be!) Containers are isolated, but less strongly than virtual machines (because modern hypervisors use all sorts of special hardware for performance and isolation, but containers share operating system resources).
Serverless Functions/FaaS: You load and run your code in the cloud provider, but you don’t deal with an underlying operating system or even container. Your code is triggered, runs, and then shuts down. It often runs in a container in a VM, but these aren’t good times for Russian doll references.
That’s a key difference between FaaS and other types of workloads: the code you load runs when triggered, not all the time. When Lambda (Amazon’s FaaS, the first on the market) was released I think it timed out in something like 30 seconds. It was very expensive to run it for more than a few seconds.
Lambda is what we use to build event-driven applications. The function is triggered and passed some data, it does something fast, sends out results, and then resets itself for the next request. Here’s where it gets really cool: you don’t need to worry about scaling or performance (okay, that’s not really true once things get big enough, but stick with me for now). If I send in 1 event on my event bus, it triggers one lambda. If I send in 10,000 events at the same time, 10,000 lambdas run in parallel. I pay for every invocation, but I don’t pay a penny when the lambda is just sitting there without any events.
Lambda functions are ideal for the kind of application we are building. It’s lightweight, I never need to worry about a server or a container, and I don’t need to patch or maintain anything other than my own code. It doesn’t cost anything when there aren’t events, and for many architectures it’s super cost effective. And yes, you can support complex application logic using multiple lambdas, event buses, message queues, and other components. These designs also scale really really well. If you are going to build a new startup thingy, go event-driven and serverless as much as possible.
Lambda Security 101
Let’s start with how lambda functions work:
You create a function, and provide your application code and configuration options — we’ll talk more about these later in this lab.
Your function uses an IAM role. Every function needs a role, and you want to use least privilege.
You trigger the function from the outside. This can be an EventBridge rule, an SNS notification, an SQS message, direct invocation from a URL, from a load balancer, an API gateway, or more.
When a function is triggered you pass in the event or data for it to process.
The function runs. It uses that IAM role, and you can add in things like environment variables, or even connect it to a VPC if it needs network access.
If you don’t put it on a VPC, it can access the Internet using Amazon’s network. We’ll discuss this in future labs.
The function sends its output wherever you specify in its code.
By default the function logs to CloudWatch Logs.
When it’s done it’s done. That function ends execution. Depending on how things are set up and what’s going on at the time, the runtime environment may also tear itself down.

Sure, there can be a lot of security nuance with lambda functions, but the fundamentals are pleasantly straightforward. Here are Rich’s 6 Fundamentals of Lambda Security(TM):
Control who and what can trigger your function. I’ve found some unsecured/unauthenticated ones during assessments.
Use a least-privilege IAM role for the function. A few times not only have I found unsecured functions, but they had full-admin IAM roles.
Write secure code. Okay, we’ll try not to screw our code up, but in an enterprise you want to use ALL the code scanning tools. And keep your code up to date if you include other libraries which might become vulnerable.
Don’t store secrets in your lambda function or the environment variables you configure when you set it up. Pull from a secrets manager instead (specifics will be a future lesson).
Write your code to log prolifically. There are frameworks available to make this better.
If you need to access internal resources (e.g., databases) put your lambda on a VPC and don’t use the default AWS network access.
That’s most of it. Our application is relatively simple so we won’t need secrets management or network access, but you’ll see the rest in the lab.
Key Lesson Points
Serverless functions are a key workload type, especially suited for event-driven applications.
Serverless functions still run on servers under the hood, but we don’t need to patch or maintain anything other than our own code.
Security focuses on secure code, triggers, IAM, secrets management, logging, and network security.
But, as always, it’s mostly IAM.
The Lab
For this lab we will implement our first Lambda function and trigger it using the EventBridge infrastructure we already built. The function is super simple and just logs the event to CloudWatch Logs, but that validates our application logic and that all the right pieces are connected.
In our next labs we’ll start building out the actual coding logic in Lambda and modify our function and its IAM privileges as we go.
Video Walkthrough
Step-by-Step
Go to your IAM Identity Center sign-in portal > SecurityOperations > AdministratorAccess > IAM > Roles > Create role:
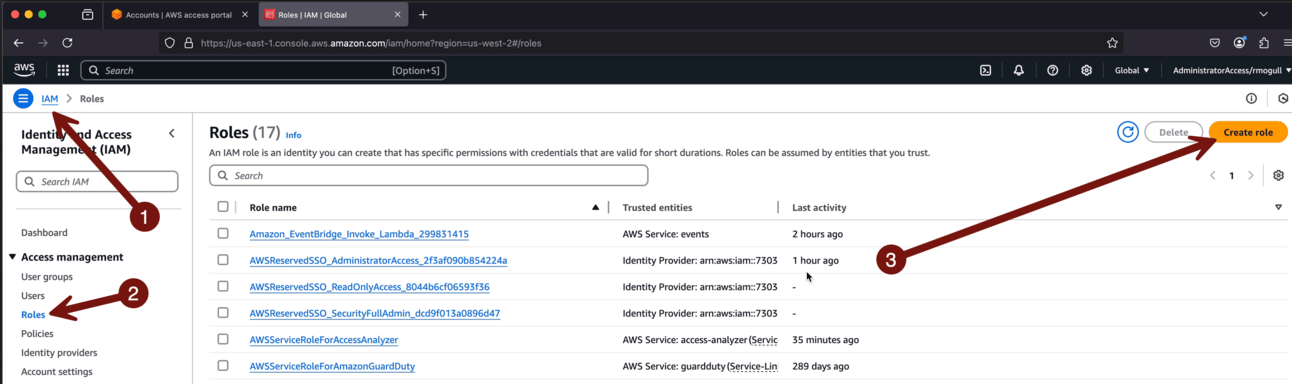
Choose AWS service > Lambda > Lambda > Next. This will create a role for lambda to use. Behind the scenes it’s basically just automation to set up the Role Trust Policy. If we were doing this via API or CLI we would need to write/include that policy ourselves.

Do not add any permissions!!! Just scroll down and click Next. We will add permissions in a minute using an inline policy, since this is a set of permissions we won’t use anywhere else. It’s also an excuse for me to show you inline policies (which live alongside the role and can’t be used anywhere else) vs. managed policies, which we’ve been using previously.

Use the role name lambda-slaw-s3. Then scroll down and Create role. I’m not worried about a description on this one — that name is spiffy on its own.

Now click the lambda-slaw-s3 role:

Then Add permissions > Create inline policy:

Select JSON and then Copy and paste this policy. There are three statements in here, and in a moment we’ll swap in your account ID. This policy is for the Lambda we are about to build. It:
Allows the Lambda function to create a log group in CloudWatch Logs.
Allows the function to create a new stream each time a function launches (this is how it works) and to store events in the stream. This is hard-coded to the name we will use for our function when we create it (security-auto-s3, showing my usual lack of creativity).
Allows various S3 read API calls.
Anyone notice the flaw in what I’ve done here? As written this onlys allow access to S3 in this account. If you remember, IAM permissions apply only where the policy lives. We’ll actually need to change this up later for cross-account access, and we’ll need to push out a role with CloudFormation StackSets in our other accounts for this function to assume. But for today this is fine, since we aren’t making cross-account calls yet, and it will help us understand that process when we get to that lab (like, probably the next lab).
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:us-west-2:<accountID>:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:us-west-2:<accountID>:log-group:/aws/lambda/security-auto-S3:*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketAcl",
"s3:GetBucketPolicy",
"s3:GetBucketPolicyStatus",
"s3:GetBucketTagging",
"s3:GetBucketLocation",
"s3:GetBucketPublicAccessBlock"
],
"Resource": "*"
}
]
}
Now you need to get your account ID from the upper right corner and paste it to over <accountID> in two places in the policy.


Then Next > name it lambda-S3 > Create policy:

Phew! We’re done with IAM (for now). To review, what we just did was create a role for our lambda function. That role can log things and access S3… in the same account. Yeah, my bad, we’ll talk more about this, probably in the next post when we set up cross-account access.
So where does that leave us? It’s time to create our function! Go to Lambda > Create a function:

On this next page we set all the core configuration we need:
Function name: security-auto-S3 (case matters — this is hardcoded into our IAM policy).
Runtime: Python (3.13 is the current version as of this writing, but whatever is the default python will work).
Architecture: amd64. Either architecture works, but AMD in AWS tends to be cheaper with better performance across the board.
Permissions > Use an existing role > lambda-slaw-s3 to use the role we just created.
Then Create function.

Before we swap in our code, let’s look at the default python lambda function.

I’m not here to teach you how to code, but … I think I need to teach you how to sorta code. Like, just enough to get by. This is very simple: first it loads up the python library to read json because everything in cloud is json (events, policies, etc.) and the odds are nearly nil that you would ever not need this library.
Then we have the “lambda_handler” function. This is the part of the code which the lambda service will call when triggered. It takes the event and the context, both of which are passed in by EventBridge (or another trigger). Not all your functions will start in this exact way, but it’s exactly what we want for our design.
Then there’s the “return” statement, which is what the function returns to the service when it’s done running. By default this logs to CloudWatch.
Okay, so let’s look at our code:
import json
import logging
# Configure the logger
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
"""
Lambda function that logs the incoming event to the default CloudWatch log stream.
Parameters:
event (dict): The event data passed to the Lambda function
context (LambdaContext): The runtime information of the Lambda function
Returns:
dict: A response with statusCode 200 and the logged event
"""
try:
# Log the entire event as JSON
logger.info(f"Received event: {json.dumps(event, default=str)}")
# Log some context information
logger.info(f"Function name: {context.function_name}")
logger.info(f"Request ID: {context.aws_request_id}")
logger.info(f"Remaining time: {context.get_remaining_time_in_millis()} ms")
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Event successfully logged',
'event': event
}, default=str)
}
except Exception as e:
# Log any exceptions
logger.error(f"Error processing event: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps({
'message': 'Error processing event',
'error': str(e)
})
}In our case we add the logging library for better log messages. If we didn’t use that we could just use print statements. Our function handler is the same, taking the event and the context, but then we change things up. We take the event and dump the event right into our log stream (you’ll see this soon enough). Then our exit message is that we successfully logged the event. The try/except are to catch potential errors “try this, and if it fails, then do that”.
More words, like a bunch more words, but this basically says “log the event, and log if it was a success or failure”. And while this will work for any event, as you’ll see we are only triggering it from our S3 events we built out last week (once we add the trigger).
Now copy and paste the code into the window, then click Deploy to make it active. Remember, there isn’t any concept of saving — a live function is a live function, so “Deploy” is the right word: we are deploying code. (And Lambda can track versions).

If you want to see some other settings which affect security but we aren’t using, check out the video or feel free to look around (just don’t change anything). Your function is all loaded up and ready to run, we just need to set a trigger and test it.
Got to EventBridge > Rules, choose the SecurityAutomation event bus, S3-security-remediations:

One of the cool things about EventBridge rules is that they support multiple targets. Our existing rule sends us an email via SNS, and we can add a second target to trigger our lambda function. For now we’ll keep both because this helps us test — if we get the email but don’t see the log message, we know that the trigger works but the function has an issue.
Go to Targets > Edit > Add another target:


Then use the following settings:
AWS service
Lambda function
security-auto-s3
Use execution role
Create a new role for this specific resource
If you decide to look at the IAM role created, it has permissions to invoke the lambda. Since this is one AWS service talking to another, you absolutely need this permission.

Then just click through Next > Next > Update rule.
To save you some pain, if you go into the lambda function there is a section at the top which lists triggers. For whatever reason ours won’t show, and I suspect it’s because we are using a custom event bus. Don’t worry — I tested everything and it works.
Now close the tab and go back to your sign-in portal > CloudSLAW > Administrator access > Switch role to Production1. We will drop into our Production1 account using the OrganizationAccountAccessRole again to create a tag on our S3 bucket. If you are using the same browser as the last lab you can drop into the account with one click. If not, just review how to switch roles into this account from last week’s lab (I’m worried this is getting so long it might be filtered by mail servers):


Go to S3 > whatever you called your bucket > Properties > Tags > Edit and add a tag. You can review the screenshots from the last lab if you need — I’m definitely taunting the email delivery gods with this long lab.
Last step. First of all, you should already have an email triggered by the change. Now we want to go back into our SecurityOperations account to see if our lambda function logged to CloudWatch. So Close the tab > sign in portal > SecurityOperations > AdministratorAccess > CloudWatch > Log groups. You will only see a log group if it worked. Then click your log group:

It worked! Yeah, this was a lot for one lab, but my video clocked in right at 31 minutes so I’m calling that within the margin of error for my 15-30 minute rule. Now feel free to click any of the log streams and read the messages. Every single function creates its own stream when invoked. When operating at scale you definitely want to keep an eye on costs, but logging is critical for security so I wouldn’t cut corners here. The devs should be paying the bill anyway.

Now we have our alerting infrastructure set up, and we know we are passing selected S3 events into our central event bus and lambda. Next up we’ll fix up our permissions for cross-account access, then we’ll have a few labs working through the code to meet our requirements.
Yes, this series is a lot, but I haven’t seen any good tutorials out there to walk you through every piece of the process to build out autoremediation (or even an event-driven application). Could I have just dumped some CloudFormation on you? Well, yeah, but that makes it tough to learn how to architect and implement for yourself in a different context.
-Rich
Reply