- Cloud Security Lab a Week (S.L.A.W)
- Posts
- Stage Set: The Cloud Incident Response Foundation
Stage Set: The Cloud Incident Response Foundation
Sit back, relax, and enjoy some light reading this week instead of a lab as we review where we are and where we're headed, continuing down the incident response road.
Rich Mogull
September 11, 2025 • Estimated Reading Time: 5 minutes
CloudSLAW is, and always will be, free. But to help cover costs and keep the content up to date we have an optional Patreon. For $10 per month you get access to our support Discord, office hours, exclusive subscriber content (not labs — those are free — just extras) and more. Check it out!
I realize you're probably asking yourself, "What the heck is a 'stage set'"?!? "Where's my lab?" Or "couldn't he at least have done a stage check with a video?!?!" Or maybe even, "did he get his nested quotes correct in the first sentence, and would those work in Python?"
Well, you see, sometimes when you run a long-term newsletter/blog/training program, you get caught up in the absolute relentless pace, and realize you mighta missed a couple of things or need a small breather.
Today, my friends, is one of those days.
I try to write these labs as if they exist out of time, since some of you see them the day they release but many more won't see them for over a year. But sometimes the real-time version of my life interferes with getting out timely labs, and rather than have a big gap I thought this would be a great time to zoom out and discuss the big picture of what we have been building with recent labs. Unlike a stage check we aren't finished yet, but I realized as I looked back at what we've covered that I wasn't doing a great job of providing very important context. Sure, some of it is in there, but we are pretty deep in the technical weeds so it's easy to lose perspective.
Let's clip in, hang back, and enjoy the mid-wall view for a moment (yeah, that's a rock climbing reference). I'm going to break out the main components of cloud incident response, show you where our labs fit in, and give you a preview of what's next. And I'll try and keep it all to about 7 minutes of reading time. This is absolutely one of my favorite topics, having built multiple Black Hat training classes on it and integrating it into the Cloud Security Alliance CCSK course and a few other places.
Oh — no video for this one, at least not yet. I'm writing it on an airplane as I head out to speak at 2 different events in 2 different countries. Like I said, life's been busy.
Cloud Incident Response 101(ish)
The TL;DR is that across our labs, in some cases going back to the first few months of CloudSLAW, we've been slowly building out a pretty robust incident response program. There's still a lot to do, but we've made some big strides.
Our overall objective is to effectively detect and respond to security incidents.
Simple enough, eh? But to do that we need to:
Collect the right information.
Detect security incidents.
Have the data and skills to analyze and investigate.
Use it all to contain, eradicate, and recover.
There are a few different incident response frameworks out there, and I semi-normalized them when building my CSA and Black Hat classes. Here's a slide I stole from the official CCSK training (Certificate of Cloud Computing Security Knowledge, from the Cloud Security Alliance... which I wrote):

You have completed multiple labs on preparation, detection, and analysis. Now let's see where that all fits.
Preparation Step 1: Feeds and Speeds
The very first thing we need for incident response is the right security telemetry to detect and analyze/investigate incidents. What's security telemetry? Basically, any logs or other information sources germane to security. This can potentially include any and every log file and event source, but some sources are better than others for security.
It's also critically important to know the timing of these security feeds, especially in cloud. It's hard to overstate the speed and scale of operating in the cloud, and this is just as true for attackers as for defenders. Attackers today are highly automated, work directly with cloud APIs, and can decimate environments in seconds or minutes. In the early days of cloud many organizations fed their cloud data into their on-premises Security Information and Event Management (SIEM) tooling, then had teams work exclusively from that data. The problem is those pipelines can take an hour or more before coughing up the data, so they were always working behind the attackers.
You don't need everything in real time, but you do need to know which sources you're collecting and how fresh the data is. Feeds and speeds.
Our labs set up a good core:
CloudTrail data for all accounts and regions, saved to S3 with about a 5-15 minute lag. This is the most important log source for our cloud management plane, and our primary tool for detecting AWS-native attacks.
CloudTrail data is also available in near-real-time via EventBridge, but only when we push out EventBridge rules into the accounts using CloudFormation StackSets.
Security Hub for all accounts and regions, which is available in the service itself (we aren't saving it to S3 yet) with all alerts sent to email. Security Hub alerts are real-time, but the services that feed Security Hub have their own timings:
GuardDuty, which is currently our main "intrusion detection" for cloud. Some GuardDuty alerts are pretty quick, but most don't appear for 20-40 minutes after the offending activity.
Access Analyzer for detecting publicly exposed resources (it can do more, but that's all we have set so far). It's pretty quick in my testing, but I don't have a good enough sense to give you consistent timing.
We've dabbled with some other logs, but haven't built much to use them yet. These are also of lower security value. Not "no security value" — just lower.
CloudWatch Logs, which in our case is mostly storing logs from Lambda functions.
Session Manager logs which we learned about in Enabling Logs in Session Manager.
It's a good start. Here's a short sample of sources we haven't touched yet:
Network logs (DNS and VPC Flow logs).
Workload/system logs from instances (and containers, which we aren't using yet).
Load balancer and API gateway logs.
Logs from S3 "data events" (accessing the data — we do get management events like changing configurations).
I personally categorize sources based on two broad criteria:
Are they security specific (GuardDuty and most security tools), or operational logs which also have security value (CloudTrail)?
Is the source logs, events, or from tools? How can I use it for threat detection? Let's talk about that one for a moment...
Preparation Step 2: Threat Detectors
Different sources play different roles in threat detection and analysis. When I first started training traditional incident responders in cloud I found it helpful to break them into these categories. This one comes from my Black Hat training (okay, it's also in the CCSK):
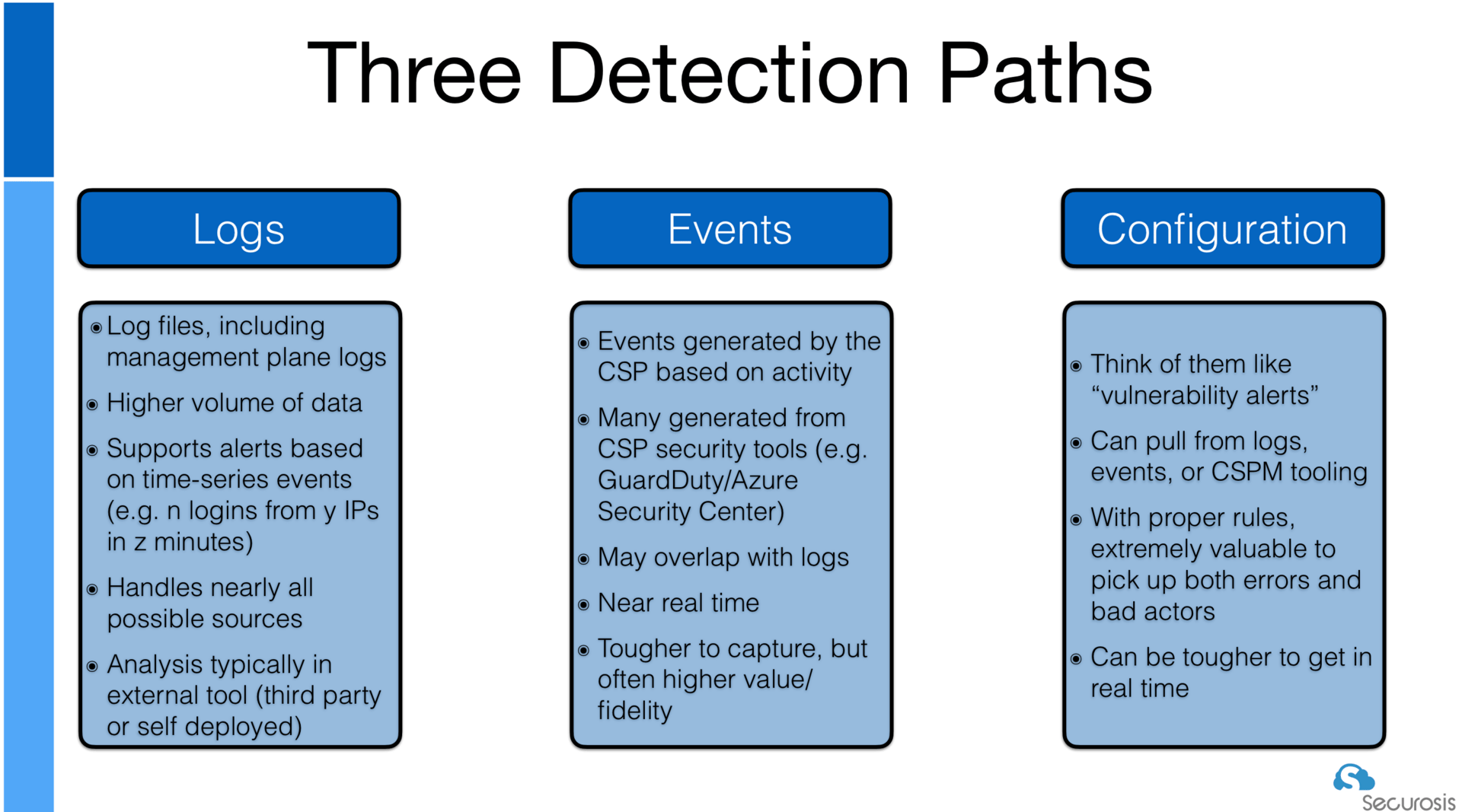
In recent labs we built threat detectors for two of these three source types:
Logs: That's what we did with Build a Time-Based Threat Detector with Lambda and Athena.
Events: Most recently we built this with Build a Real Time Threat Detector with IaC.
We also receive alerts through Security Hub, per Use EventBridge for Security Hub Alerts. This feeds us everything from GuardDuty and Access Analyzer.
Configuration: We get a little of this from GuardDuty, and a little from when we built out S3 autoremediation for exposed buckets (Schedule Security Scanning with a Serverless Fanout Pattern) But this is really about CSPM, on which we will soon have labs.
Hopefully this gives you some perspective on how these preparation labs fit together. We aren't done with the topic by any means, and will be integrating more sources and building more threat detectors in future labs, as well as learning about detection as code, but we've largely covered the core concepts for Feeds and Speeds and detection engineering.
Analysis
Okay, our threat detector fires... so what now? Panic? Send Rich an email begging for help? Nah, you got this. Weirdly, I covered analysis before threat detection in Getting Started with CloudTrail Security Queries, since we needed to learn about Athena and queries. These labs are a decent introduction to basic analysis of management plane events, and we even simulated a full attack in our Skills Challenge and Skills Solution. Remember my RECIPE PICKS mnemonic?
And yes, more later. Of course. :)
Where We Are, Where We're Going
Cloud incident response is an entire career, so there's no way we can cover everything, but at this point we have a good foundation. We have:
Prepared our AWS Organization by enabling fundamental security feeds.
Built threat detectors based on data in our logs, cloud events, and cloud security tools.
Learned the basics of analyzing an attack with a live simulation.
The big gap in these labs is our lack of discussion on cloud configuration management and how that fits within incident response. We also haven't discussed managing threat detectors. These are both huge topics, so I'm engineering some nice labs to cover the basics and give you ideas for more to explore on your own.
Well, they just told me it's time to detach my keyboard from the iPad so the plane can land. Hopefully this has helped you orient yourself, and understand how these labs all fit together.
-Rich
Reply